Hive窗口函数总结
窗口函数是对Hive的一项增强,用来更方便地分析离线数据。窗口函数的使用场景非常之多,包括去重、排名、分组求和等等。本文希望尽可能全面的归纳窗口函数的用法,以便日后的查阅。
窗口函数
基本用法模式
<FUNCTION>(<params>) OVER (<window>), 表示对window内的元素进行function操作,这里的window可以理解为分组,例如partition by col1 order by col2 desc ,即”相同的col1分为一组,按照每一行对应的col2的值倒序排序“。function即对每一组采取的操作,比如取平均值,这样可以得到对每一个不同的col1的col2的平均值的表,即:
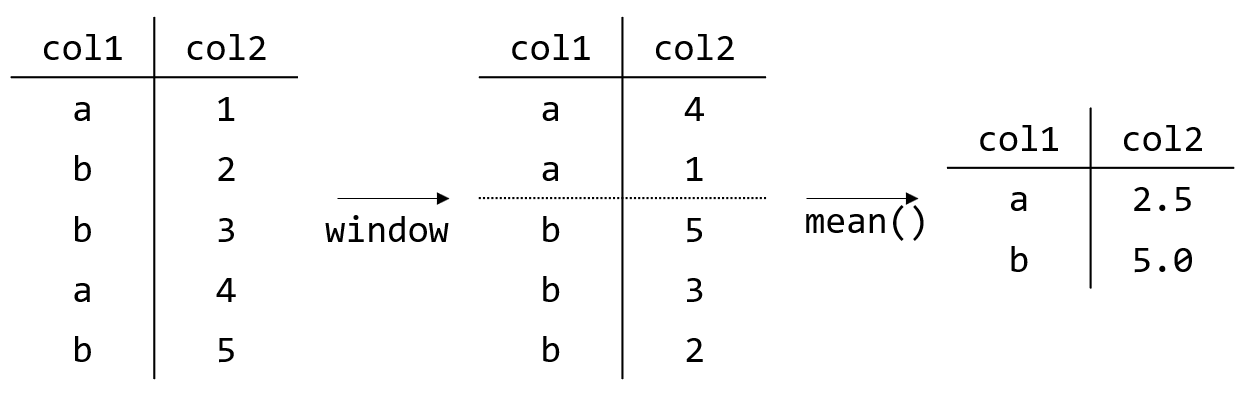
该操作的hive语句:
SELECT col1,
col2,
AVG(col2) over (partition by col1 order by col2 desc)
FROM test_table
[where ...];
Lead & Lag
LEAD(col, n, DEFAULT): 用于统计窗口内往下第n行值。col指定列名,DEFAULT指定如果往下n行没有值了的替换值,如不指定则是NULL。
LAG(col, n, DEFAULT): 用于统计窗口内往上第n行值。col指定列名,DEFAULT指定如果往上n行没有值了的替换值,如不指定则是NULL。
FirstValue & LastValue
FIRST_VALUE(col, NO_NULL): 用于统计窗口内截止到当前行的第1行值。col指定列名,NO_NULL指定是否跳过空值,默认TRUE跳过。
LAST_VALUE(col, NO_NULL): 用于统计窗口内截止到当前行的最后一行值。col指定列名,NO_NULL指定是否跳过空值,默认TRUE跳过。
Aggregation Functions
COUNT(col):计数SUM(col):求和MIN(col):求最小值MAX(col):求最大值AVG(col):求平均值
Ranking Functions
注意排序已经在window语句中执行了。
ROW_NUMBER():求该行在window中的行数,从1开始,遇到重复值的按窗口出现的顺序递增排列。常用于取前n个记录,比如取用户最近一次冒泡时间。RANK():求该行在window中的排名,重复值的名次相同,但会留下空位,比如两个第一后面是第三。DENSE_RANK():求该行在window中的排名,重复值的名次相同,不会留下空位,比如两个第一后面是第二。CUME_RANK():小于等于当前值的行数占比。PERCENTILE_RANK():(该行的RANK值-1)/(窗口总行数-1),百分数排名。NTILE(n):将窗口按顺序切成n片,如果切出来的结果不均匀,分界处的行归入上一片。
窗口子句
窗口子句可以用来更精细的描述窗口,注意有几个函数是不支持窗口子句的:Rank, NTile,DenseRank,CumeDisk,PercentRank,Lead,Lag.
| 子句 | 意义 |
|---|---|
| PRECEDING | 往前 |
| FOLLOWING | 往后 |
| CURRENT ROW | 当前行 |
| UNBOUNDED | 起点(一般结合PRECEDING,FOLLOWING使用) |
| UNBOUNDED PRECEDING | 表示该窗口最前面的行(起点) |
| UNBOUNDED FOLLOWING | 表示该窗口最后面的行(终点) |
用法实例:
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW:从该窗口的起点到当前行
ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING:从前2行到后1行
ROWS BETWEEN 2 PRECEDING AND 1 CURRENT ROW:从前2行到当前行
